You've done it. Your robotic prototype is up and running, you’ve sourced your hardware, and you're anxious to see it operating in the field. Your innovative idea is nearly a product, but for a modern autonomous system, connectivity is non-negotiable.
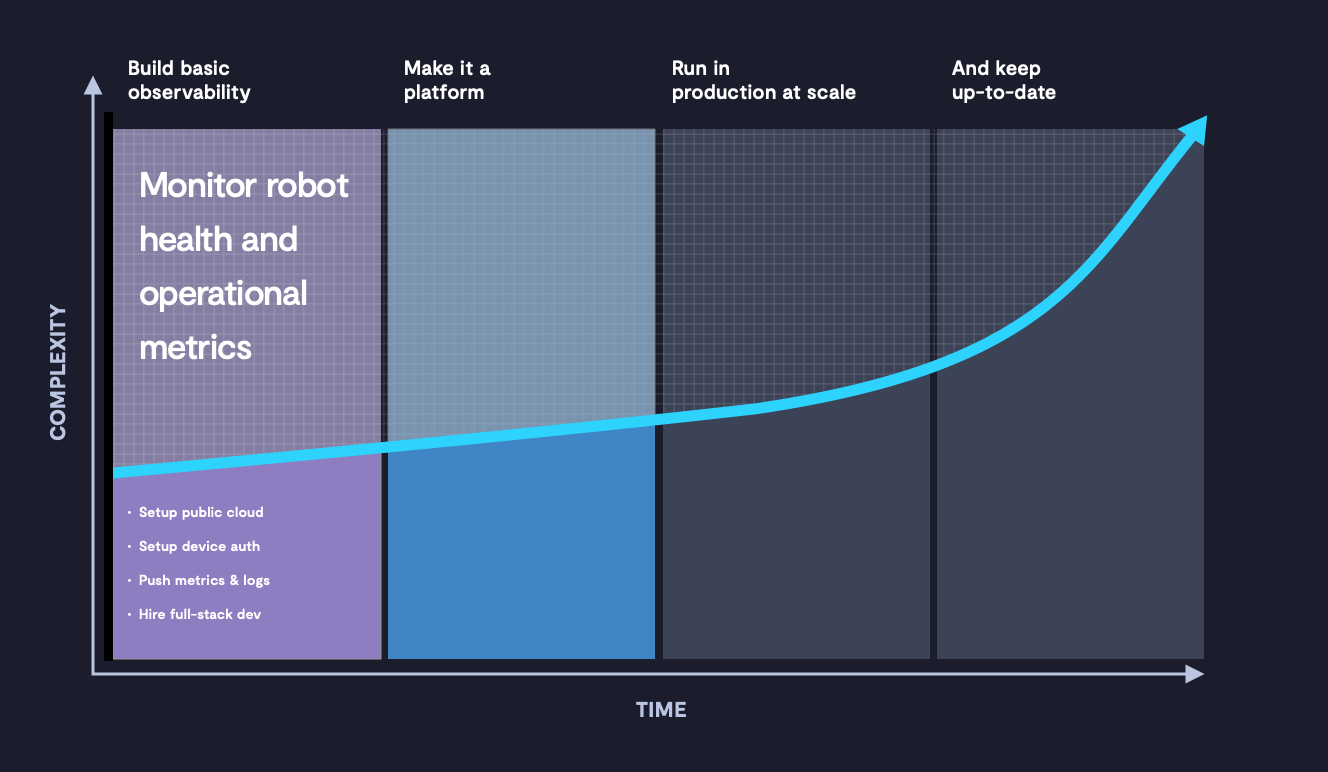
Every in-field machine must have a cloud-based backend, which means having your bot up and running around the office is far from crossing the finish line. Now that your machine is functional, it's time to get it online. This four-piece article will help you understand what precisely it means (and what it takes) to get your robot online, keep your robot online, and most of all, grow your robot online.
Here are the four (formidable) phases of robotics cloud development:
Phase 1: Building out the basics
Though this phase may consist of "the basics", very little is actually "basic" when it comes to building the groundwork for your robotics backend. This phase should come in tandem with the development of the machine itself, and will consist of things like selecting a cloud service provider (e.g., AWS, Microsoft Azure), potentially choosing an analytics platform (e.g., Datadog, Grafana, AWS Cloudwatch), and working to integrate these systems with your hardware and internal operations.
While making these decisions may seem rather straightforward at first glance, in actuality, they carry great importance for both your early operations and for the future of your business at scale. For some insights into why these decisions matter, check out last month's post on backend cloud development.
At this point, depending on the size of your team, you may either repurpose an existing engineer or hire a full-stack engineer to build the "v0" of your Robot Operation Center (ROC). Repurposing a robotics engineer requires ramping up on cloud technologies and DevOps best practices, while hiring a full-stack cloud engineer requires ramping up on robotics technologies and the fundamental elements of your application.
In most cases, the primary function of a v0 "ROC" is data retrieval. With that goal in mind, you'll want to begin by identifying which types of data are essential for you to "keep the lights on." While every robotic application is unique, there are some data formats that are commonly utilized by all of our customers:
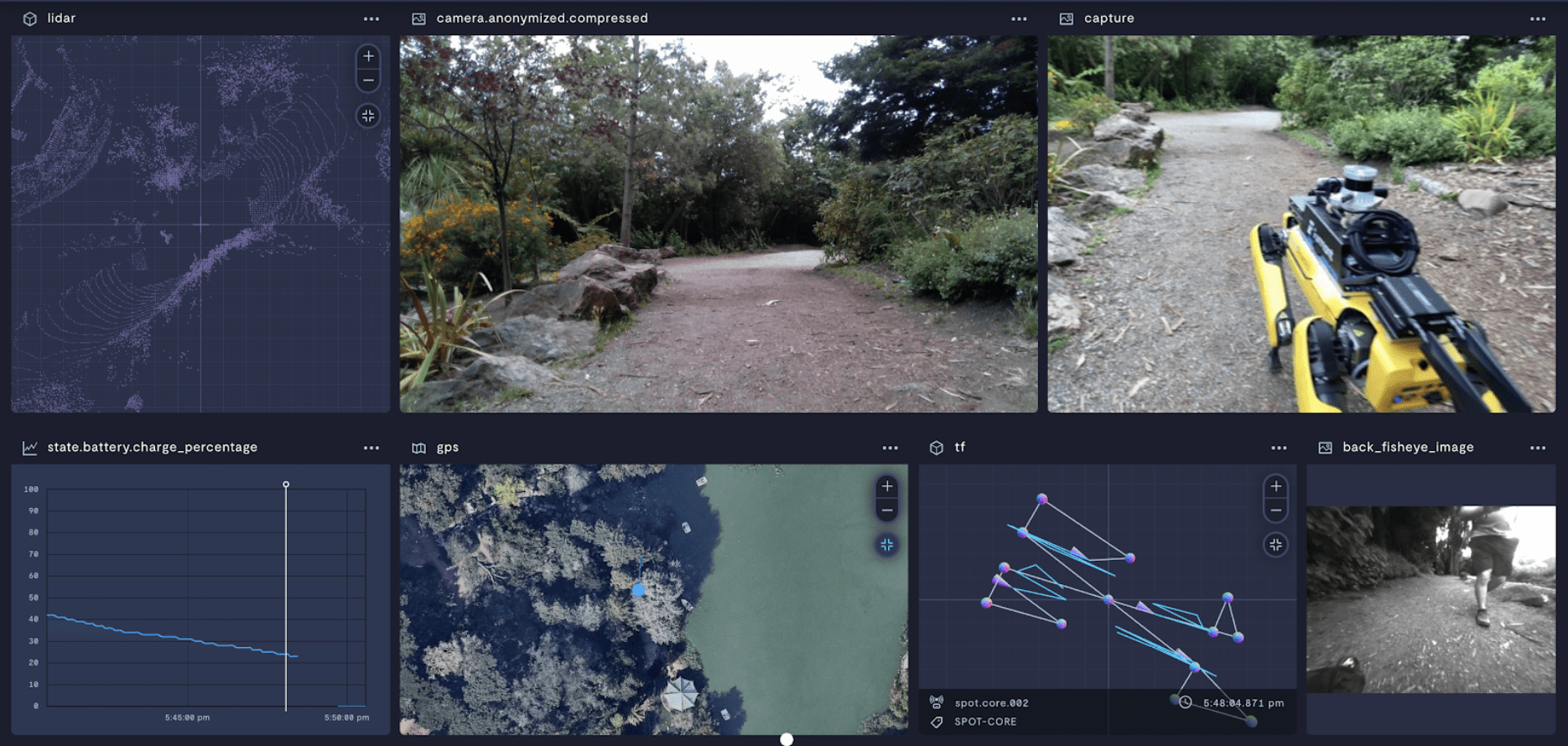
That's a lot of different kinds of data! Although we do frequently see customers working with a diverse array of data types, let's cut that list down to the absolute minimum:
- Metrics
- JSON style logs and text
These two data types are the bread and butter of most backend logging and metrics systems. Some systems are capable of handling both and can time-align them (i.e Datadog, Grafana Cloud), which is a big lift when debugging issues. Let’s talk about the steps involved to set up a standard metrics/logs platform:
Step 1: Setup authorization and authentication for your robots
There are usually two ways you can go about doing this:
- Baking an API key onto your robot
- Creating a public/private keypair and uploading the public key to the cloud service
The first option is somewhat easier but also has a higher risk associated with it. A shared API key across your entire robotic fleet will require a fleet-wide update to replace it. However, it is quite easier to bake in a key to your base image.
The second option is more secure in that it provides much more granular options. Some tools provide this as the default mechanism, and our opinion is that this should be a requirement for any fleet-deployed machine with "non-standard" cloud backend requirements —especially when physical access to the machine is required.
Step 2: Figuring out the log and metric data you’ll want to send
Depending on your system, this could be somewhat straightforward. For example, a Datadog agent can listen to all system-level metrics and collect logs from systemd's journal or from any of the Docker containers running on the system.
Another tool we like at Formant is Prometheus, which provides many different ways to get metrics from your system back to the cloud, however, the scraping implementation of Prometheus could present a few technical challenges for devices without globally available IPs.
In all of these cases, though, you will need to bake into your robot application the kinds of data you will want to retrieve and send to your metrics and logging backend. This requires SW updates, which at this stage, you may not be able to accomplish Over-The-Air.
Let’s test out one of these tools. First, let's start with AWS Robomaker. At Formant, we like the approach the AWS team has taken with their ROS Cloudwatch Node, which allows for offline data ingestion. One of the larger challenges in a robot cloud is designing a strategy for intermittent and poor network connectivity.
Setting up the Cloudwatch node is relatively straightforward. You will need to either create a set of AWS credentials per robot or use a globally available set. Make sure you restrict the permissions as described in the blog post above to just the necessary permissions. After setting up the node you will start to get your /rosout_agg messages (a common pattern for ROS logs) in Cloudwatch. You can send additional logs by using the rosgraph_msgs/Log ROS message type and sending to /rosout_agg or adding additional topics to the yaml ros param file.
Step 3: Identify and send other situational data
At this point, you will have a system for capturing logs and metrics. However, after standing all this up, you will inevitably be asked to provide more "robot-shaped" data, rather than just logs and metrics.
Very commonly we want the situational awareness we gain from data like localization, imagery, point clouds and laser scans, as well as the device’s transform tree. Engineers may also be asking for data blobs such as ROSbags for technical analysis, debugging, and training models.
There are a variety of tools to "pull" or upload large datasets such as ROSbags. In some cases a robot application or node can identify an error has occurred and use a cloud based key or token to upload to a storage bucket. At this point, you would have a very rudimentary "Bag" store, that is indexed by file name and path. For many, though, the ability to request data "On Demand" is a key requirement for minimizing bandwidth usage, as well as for root cause analysis in cases where the machine did not report any significant errors.
Step 4: Build a basic v0 ROC (Robot Operation Center)
For some companies, the strategy outlined above may not be enough. In many cases, it is necessary to build a v0 ROC that is customized to one’s unique business and application. This usually includes a robot authentication and authorization strategy, a database to hold robot metadata and its "shadow" or "digital twin", as well as some type of data lake that contains application specific time series logs and metrics. One may also require other data types such as those listed above.
For example, you may want to store camera data to train models and do manual labeling. Additionally, you will invariably decide to build a barebones frontend web application which can interact with an API layer fronting these data stores to provide business-specific operations. This also requires some application-level logic on the robot themselves with nodes for interacting with the robot “shadow” and dealing with authorization and authentication, as well as data collection nodes (similar to the ROS Cloudwatch node).
In many cases, a mashup of off-the-shelf solutions integrated with homegrown application logic is combined to build this v0 ROC. The architecture generally looks like something below:

For most applications, these four steps make up what we like to call "Phase 1" of robotic backend development. The technical implementations and costs here are similar to what some SaaS companies build as a whole business! Keep in mind, this outline also doesn’t include some very necessary components, such as software OTA, CI/CD, and remote connectivity to your machines.
In the next part of this series, we’ll go into more detail on making this a platform upon which field-facing teams (such as operations and support) can rely to root cause issues in production as well as building customer-facing solutions. Stay tuned for Phase 2 of robotic cloud development.