
This is part 1 of a 2-part series on robotics observability platforms. In this post, I’ll be covering the basics of what these platforms do, and features that these platforms contain.
What is robotics monitoring? What about observability?

As described here, there are several unique requirements when applying observability to the field of robotics.
The standard pillars of observability -- logs, metrics and traces -- are helpful but by no means sufficient. We also need context from the physical world in the form of visual and geometric sensor data, support for robotics data types, powerful metadata features, and robustness in the presence of poor network conditions.
Crucially, a robotics observability platform must support not only monitoring, for proactive detection of known failure modes, but also ad hoc debugging for the “unknown unknowns” that are so prevalent in the physical world.
A robotics observability platform pulls these features together into a unified toolset that provides visibility into, and actionability onto, your field-deployed robots.
Generally these platforms consist of three parts:
- Data ingestion
- Data transformation, storage, and indexing
- Monitoring and operational workflows
Each of these parts have their own considerations whether you are building your own tools or selecting a platform service.
Ingest
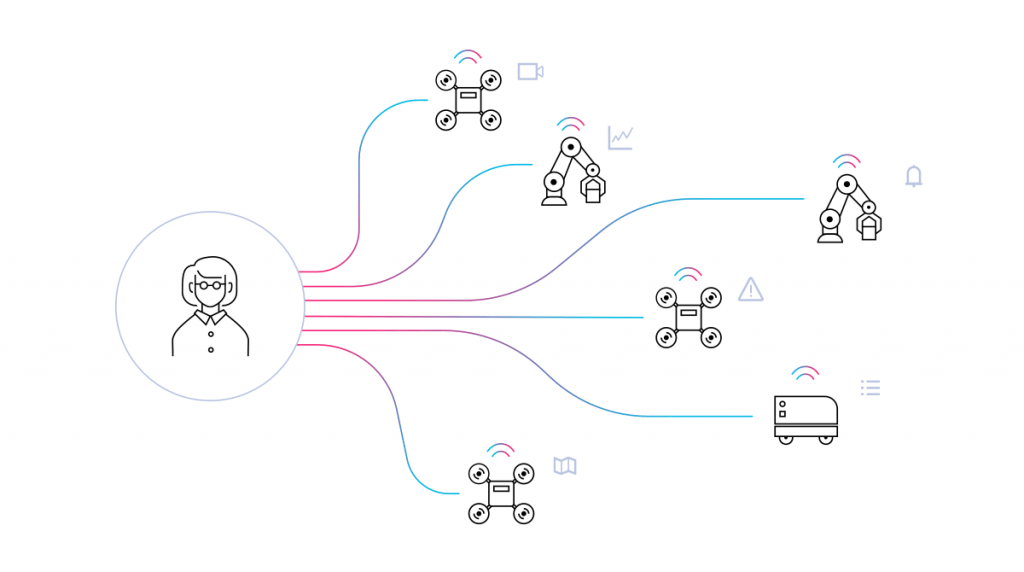
Robust data ingestion from field-deployed robot applications is hard to get right. The best data ingestion tools are easy to set up at the edge and are aware of local system properties like network health, so that continuous histories of data can stored and served to any interface. I’d expect any potential user to ask the following questions related to this area:
Ease of implementation:
- What setup is required on the device side?
- What setup is required on the cloud side?
- What, if anything, do we need to migrate from our existing setup?
Compatibility:
- Is the ingestion technology compatible with my robot system (ROS, Linux, PLC-based, etc)?
Network awareness:
- What is the behavior if network isn’t available?
- Are there quality-of-service features in case of network failure? Is data automatically stored and forwarded later?
Stream awareness and prioritization:
- Will the system ensure that my higher-value data gets to the cloud faster, and/or with more reliability, compared to non-critical data, when network resources are limited?
Transfer, protect, store
Data collected from the edge must be transformed, indexed, and stored for live or future analysis. The main concerns here are around scale, security, and data governance. These are standard questions that will come up:
Scale:
- How much data can be ingested?
- How long is the data retained?
- How soon is my data accessible from the time it was generated?
Security:
- What security practices, encryption methodologies, and protocols are used to ensure data integrity and security?
- How will your system obfuscate or anonymize potentially sensitive data, such as images of faces?
Data Governance:
- Who owns the data? Can the data be deleted upon request?
- How is my data indexed?
- Are there easy ways to export data into other infrastructure?
Observability interface
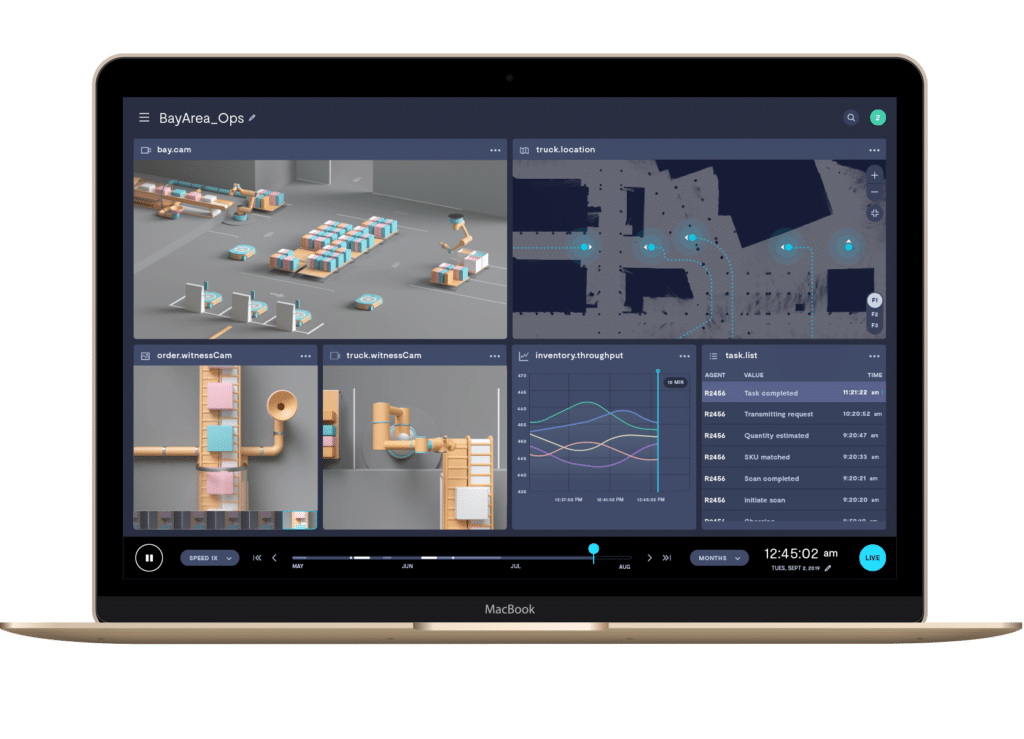
Now that we’ve got the backend covered, we get to the interactive part - the frontend tools and workflows. The right operational UI should empower team members with different skillsets all to increase their productivity, whether it’s engineers debugging, operators monitoring, or data scientists building and improving their models. We expect any standard UI to contain:
Historical debugging
- Does the tool provide a complete history of the data flowing from the field for debugging?
- Is this history displayed in a way that makes it possible to root cause faults?
Fault Detection (Monitoring)
- When robots are behaving outside of a known spec, will the system raise alerts for human attention?
Anomaly Detection
- Is the system be smart enough to flag a potential issue that we have not yet seen?
- Does the system learn over time?
Fault-correction in real time
- When a fault or an anomaly is raised, can it be corrected in real time?
- Are corrective actions safe and auditable?
Fault history
- Is there a way to track faults over time?
Fleet management
- Can robots be grouped by location, software version, customer ID, or pretty much any other arbitrary metadata?
Access controls
- Can you define which robots your team has access to, according to role and responsibility?
Audit Logging
- Is there an audit-able history of configuration changes, operator actions, and other sensitive operations?
Integrations:
- Are there integrations with other tools in your workflow like Slack and Pagerduty?
- What APIs exist for integrating the data with other systems?
Whew, that’s a lot to consider
We know - there’s a lot to consider here.
There are many features, tools, and processes to keep in mind as you consider how you will implement and scale the management of your robotic fleet. If you have any questions or would just like advice about where to start, contact us.


